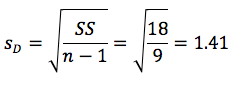Outline
|
 |
Lab 17
|
|
Hypothesis tests analyzed by related-samples t-tests
In the prior lab we examined how to use a t-test to compare a treatment sample against a population (for which s isn't known). In this lab we'll consider the case where the null population m isn't known and must also be represented by a sample (like the treatment m was in the one-sample cases. Today we'll consider situations where the two samples means come from related samples. The are two ways the samples can be related. In one case, there are two separate but related samples. In the other case, there is a single sample of individuals, each of which gets measured on the dependent variable twice. Consider the following examples:
In the first example, the situation has been decided for you, there is a pre-existing relationship between the two samples. In the second and third examples, you, as the experimenter, make a decision to make the two samples related. Why would you ever want to do that? To control for individual differences that might add more noise (error) to your data. In Example 2, each individual acts as their own control. In Example 3, the control group is made up of people as similar to the people in the experimental group as you could get them. Both of these designs are used to try to reduce error resulting from individual differences.
Okay, so now we know that for repeated-measures and matched-subject designs we need a new t-test. So, what is the t statistic for related samples? Again, the logic of the hypothesis test is
pretty much the same as it was for the
one-sample cases we've already considered. Once
again we'll go through the same steps. However,
the nature of the hypothesis, and how the t
All of the tests that we've looked at are examining differences. In the previous lab we were interested in comparing a known population with a treatment sample. Now we are beginning to consider cases when the null population m is unknown and must also be represented by a sample. The t-test for this lab also considers differences between scores from a related pair of subjects. Because the two scores for each pair are related, the differences are based on differences between each individual or matched pair.
Example of repeated-measures study (for review if you need it; otherwise, go to Excel section)
The results of the two ratings
are presented below. D stands for the
difference between the pre- and post-ratings for
each individual (Post-Pre).
Mean difference for the sample =
Process of hypothesis testing Steps 1 & 2 : State H0 & HA and set a decision criterion. Before we can state hypotheses, we need to know whether this will be a 1-tailed or 2-tailed test. All we are asking in this example is if taking statistics has an impact (any impact , in either direction) on the students' feelings about statistics. Since no direction of impact is predicted, this will be a 2-tailed test. Let's assume that α = 0.05.
Step 3 : Sample statistics
Our sample is given above
in the table with sample mean
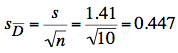
Step 4 : Test statistic
df = 10 -1 = 9.
Finding tcrit is
the same as usual, look at the table. α =
0.05, two-tailed, df = 9 tcritical
= ± 2.262 Our tobs does not fit in the critical region: tobserved < tcritical (less extreme). Fail to reject (i.e., retain) the H0. No effect of taking the stats class on liking of statistics
Okay, what about Hypothesis testing with a matched-subject design? Basically we do things exactly as we did in the previous example, except now we subtract the matched control person's score from the experimental group person. So, as an experimenter, how do we know when to use related sample designs or independent sample designs? Related samples designs are used when large
individual differences are expected and
considered to be "normal". Why? Because
individual differences can contribute to
sampling error. So by using related samples
designs, one can reduce sampling error and
have a better chance of finding a difference
if there really is one.
(1) A major university would like to improve its tarnished image following a large on-campus scandal. Its marketing department develops a short television commercial and tests it on a sample of n = 7 subjects. People's attitudes about the university are measured with a short questionnaire, both before and after viewing the commercial. The data are as follows:
Person X1 (before) X2 (after) A 15 15 B 11 13 C 10 18 D 11 12 E 14 16 F 10 10 G 11 19 (a) Is this a within-subjects or a matched samples design? Explain your answer. (b) Conduct a hypothesis test (showing all steps) to determine if the university should spend money to air the commercial (i.e., did the commercial improve the attitudes?) Assume an alpha level = 0.05.
Using SPSS to compute a related-samples (paired-samples) t-test
Now use SPSS to evaluate the following study.
Person Pretest Posttest A 15 15 B 11 13 C 10 18 D 11 12 E 14 16 F 10 10 G 11 19 H 10 20 I 12 13 J 15 18 Remember that SPSS automatically finds the difference of Var1-Var2. To have improvement be a positive score, enter Posttest as Variable1, so that the difference = Posttest - Pretest. . (2) A psychology instructor teaches statistics. She wants to know if her lectures are helping her students understand the material. So she tells students to read the chapter in the textbook before coming to class. The before lecturing the professor gives her class (n = 10) a short quiz on the material. Then she lectured on the same topic, and followed her lecture with another quiz on the same material. Was there an effect of her lecture? Assume an a = 0.05 level. The data are as follows:
Person X1 (before) X2 (after) A 15 15 B 11 13 C 10 18 D 11 12 E 14 16 F 10 10 G 11 19 H 10 20 I 12 13 J 15 18 (a) Enter the data into SPSS. Test your H0 using a paired-samples t-test. Do you reject the H0? (b) Use the 'compute' function to make a new variable that is the difference between the after lecture quiz and the before lecture quiz. Now use SPSS to compute a one-sample t-test on this new difference column (use 0 as your test value). (c) How do the results of questions (a) and (b) compare? Explain your answer.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||