Outline
- design and evaluate experiments
|
|
|
Lab 4
Designing Experiments
|
|
Generally
speaking, the research design that is used
and the properties of the variables combine
to determine what statistical tests we use
to analyze the data and draw our
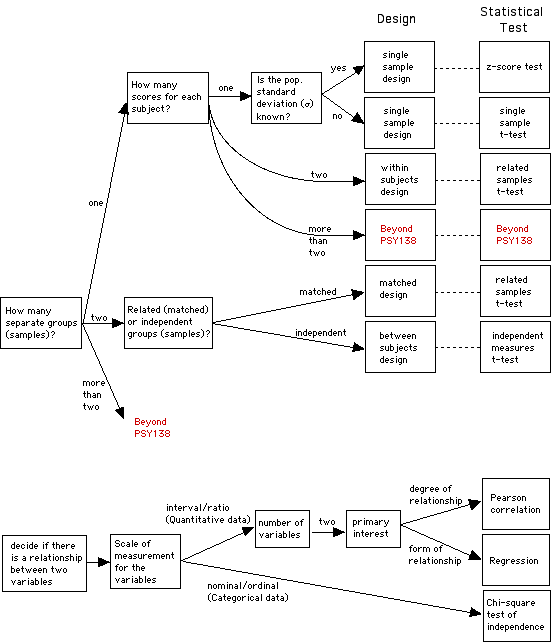
conclusions. The figure below depicts
a series of questions about these features
to help one decide what statistic is
appropriate. Today's lab will focus on the
top part of this figure that involve
experimental designs.
Part
I: Experiment basics
The Experimental Method
- A method of determining whether
independent variables are related to
dependent variables (we will focus on
designs with a single IV and a single DV).
- The researcher systematically manipulates
the environment (manipulates the independent
variable[s] and controls all other relevant
variables either by randomization or by
direct experimental control) to observe the
effect of this manipulation on behavior.
- The method allows a causal inference
to be made: Any change in the dependent
variable was caused by the manipulation of
the independent variable
Designing an Experiment
At the heart of an experiment is a comparison
between two (or more) conditions. In other
words, you (the experimenter) will always be
comparing at least two things. This may include
comparing your sample with a known population,
or two (or more) different samples (groups)
against each other, or even multiple scores
within a single sample of individuals.
Generally the process involves a number of
steps:
- identification of your research questions
- identifying your variables of interest
- specifying your hypotheses (how are the
variables related to one another)
- selecting a research design
- collecting your data, analyzing your data
- drawing conclusions from your data about
your hypotheses.
Let's consider an example: Consider the
steps that one may go through trying to design
an experiment to test the following claim: Claim:
Chocolate-covered peanuts enhance memory
- Construct a formal hypothesis
e.g., chocolate-covered peanuts improve
recall scores from a list of unrelated
nouns.
- Identify the independent and dependent
variables.
IV: consumption of chocolate-covered
peanuts
DV: a measure of memory performance
- How to manipulate the IV
the presence or absence of m&m's.
- How about manipulating the quantity of
m&m's
- Do we need a control group, a placebo? Any
other control variables?
- Identify the how we'll measure the DV.
- Any operational definitions or constructs
needed?
- Are there any subject relevant variables
(use randomization and matching)
Are the effects the same for all sexes?
Ages? Majors?
- Situation relevant variables (test
conditions, experimenter behavior, timing)
e.g., the list of nouns, how fast given
Identifying your Variables
GO TO LAB 4 ASSIGNMENT and
type up your answers to the following questions.
1. For the
following descriptions, identify the different
variables.
a) A doctor
suggests to you that the drug triazolam
(marketed as Halcion¨) helps "reset the
body's clock" for people experiencing jet
lag. You conduct an experiment to test
this hypothesis. Fifty people are flown
from Atlanta to Tokyo. During the flight,
half the flyers are given a dose of
triazolam. The other half are given a
harmless sugar pill. Six hours later, all
subjects are asked to rate how sleepy and
disoriented they feel.
b) Two new drugs,
ZZT and Glomulin, are believed to slow
the progression of AIDS-related
syndrome. To determine their
effectiveness, the Food and Drug
Administration authorizes a clinical
test. Thirty HIV-infected patients are
given each drug. In both groups, 20
patients show no signs of AIDs-related
complications a year later. The
researchers conclude that the drugs are
equally effective in combating the
symptoms of AIDS.
2. A researcher wants to know if brighter
lights make factory workers more productive.
Workers in a factory are randomly assigned to
2 groups. One is moved to a new factory next
door where the factory lights are brighter.
The other group stays behind in the old
factory. The productivity of the 2 groups is
compared.
- Identify the independent (or
explanatory) variable(s).
- Identify the dependent (or response)
variable(s).
- What is a plausible
confounding variable?
3. A researcher wants to know if it helps
patients if their therapists disclose personal
information about themselves. Participants are
randomly assigned to 1 of 2 groups. One group
has therapists who previously have indicated
that they tend to disclose a lot about
themselves in therapy. The other group has
therapists who previously have indicated that
they rarely disclose personal information in
therapy.
- Identify the independent (or
explanatory) variable(s).
- Identify the dependent (or response)
variable(s).
- What is a plausible
confounding variable?
Selecting your experimental designs.
As mentioned above your experiment
will involve a comparison between at least two
groups. But there is more to an experimental
design than the creation of two groups. There
are a number of different ways to create your
two (or more) groups.
- Levels of your independent
variables - there needs to be at least
two different values (levels) of your IV You
may handle the different levels of your IV
in two different ways
- Independent (between) and Related
("within" or "repeated" and "matched")
variables
- independent samples - you
manipulate your indpendent variables
across separate groups of people (so
each level of your IV is given to a
different group/sample of
individuals)
- related samples - have
everybody get all the different
levels of your IV.
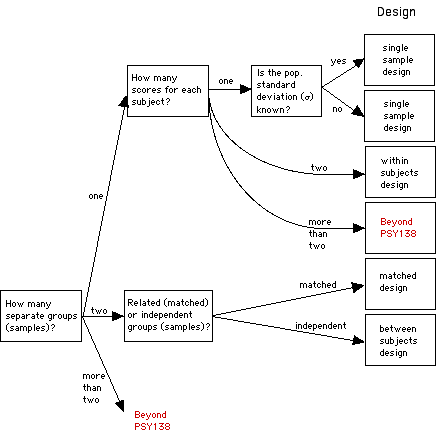
Below is a decision tree that lists some
common experimental designs. If you open the
chart by clicking on the button, you will see
a larger version of the chart with the kind of
statistical analysis test that is used to
analyze each one. Later in the course we'll be
learning about how to conduct (some of) these
statistical tests.
How do we use the decision tree?
An example
Suppose that you (a stats instructor) are
interested in how well your lecture on
experimental design worked. So you decide to
test your students before and after the
lecture. Both tests are designed to measure
the students' knowledge of experimental design
issues.
what kind of experimental design is this?
Go through the questions in the tree.
- How many groups (samples) of people do you
test? 1
- How many scores (pieces of data) do you
collect from each person? 2
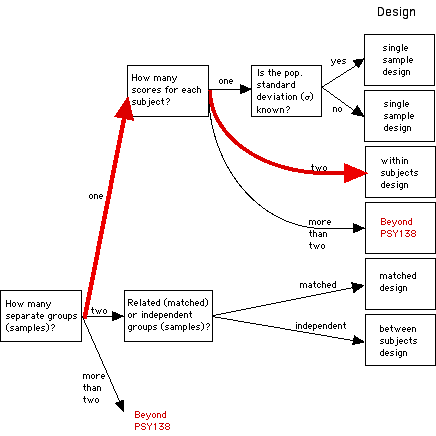
This leads you to a "within-subjects
design ." You've got one group, with two
scores (pre-test scores and post-test
scores) from each person (so the scores
are "related" to each other by virtue of
being from the same people). The IV here
(2 levels: before lecture and after
lecture) is being manipulated as a "within
groups" variable
Part
II: Group Project (form a group at
the table nearest you).
Your group's
task is to take the issue below
assigned to your group by the lab
instructor and design an experiment
(or series of experiments if you deem
it necessary) to examine it.
1) Does watching violence on TV cause
violent behavior?
2) Does playing video games improve
hand-eye coordination in other
tasks?
3) Does smoking cause lung
cancer?
4) Does studying with background music
improve test scores?
5) Does living in a large city
decrease helping behaviors?
6) Does color affect mood?
7) Does caffeine affect work
productivity?
Be sure to include information about:
what are your variables, how will you
manipulate your independent variables,
how will you measure your dependent
variables, what control conditions do
you need, who are your participants,
etc? Make sure that you give enough
thought and detailed discussion to all
of these issues. |
4. Individually, type up
a description of the experiment that your
group designed (including the information
mentioned above). Then spend some time
evaluating the experiment that your group
designed.
You should consider the
adequacy of:
- the way the dependent
variable(s) is/are measured.
- the way the
independent variable(s) is/are
manipulated.
- are there enough
appropriate control conditions?
- can you think of any
potential confounds?
- using the decsion
tree, what design would you use to
describe your experiment?
|
Part III. Experimental designs and SPSS data
format (looking ahead a bit)
The design that you use for your
experiment (or more generally your research
design) will determine, in part, how you set
up your SPSS datafile. This is
another example of the importance of needing
to know the context of your data.
For some designs, the data for different levels
of the Independent Variable (IV) will be set up
in separate columns. This allows SPSS to
be associate particular data points with matched
data points. For example below you see a
screenshot of a datafile that compares a sample
of individuals who were in a study that compared
their jumping performance before (Jump1) and
after (Jump2) an experimental
manipulation. For this analysis, SPSS
needs to "know" which jumps correspond to which
individuals because the mathematics compares, on
a person-by-person basis their first jump with
their second jump. The way SPSS "knows"
this is by putting these data points in the same
rows. Notice the the data points are the
measurements of the Dependent Variable (DV) in
the different levels of the IV.
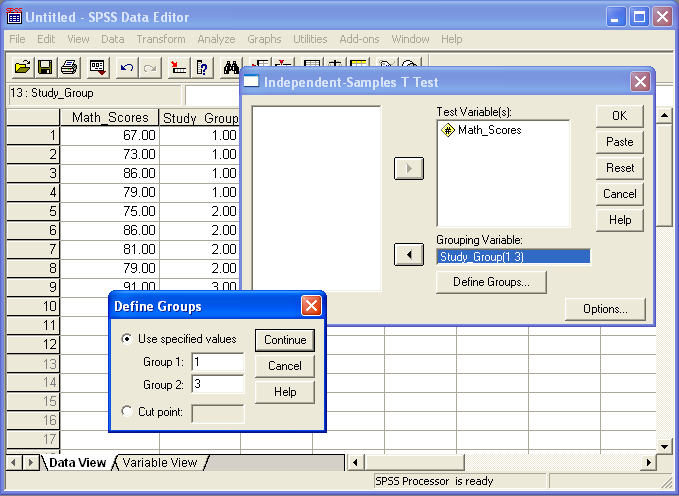
For other designs your Independent variable
will be in a single column, with values in
that column specifing the levels of that
variable. These are situations where the
computations don't rely on pairwise
comparisons of specific data points. In
these designs, the data points for the DV are
in a separate column. Computationally,
all SPSS needs to "know" is which scores are
in which levels of the IV. There is no
need to specifically match specific datapoints
together. Below is a screen shot (from a
an older version of SPSS, but the details of
the point here are the same).
Math_Scores are the scores for the DV.
Study Group are the levels of the IV.
|
|