A First Course for Students of Psychology and Education, 4th Edition. New York: West Publishing.
So far we've discussed two of the three characteristics used to describe distributions, now we need to discuss the remaining - variability. Notice in our distributions that not every score is the same, e.g., not everybody gets the same score on the exam. So what we need to do is describe the varied results, rougly to describe the width of the distribution.
-
Variability provides a quantitiative measure of the degree to which scores in a
distribution are spread out or clustered together.
In other words variablility refers to the degree of "differentness" of the scores in the distribution. High variability means that the scores differ by a lot, while low variability means that the scores are all similar ("homogeneousness").
The simplest measure of variability is the range, which we've already mentioned in our earlier discussions.
-
- The range is the difference between the upper real limit of the largest
(maximum) X value and the lower real limit of the smallest (minimum)
X value.
So look at your frequency distribution table, find the highest and lowest scores and subtract the lowest from the highest (note, if continuous must consider the real limits).
__X f cf c% 10 2 25 100 9 8 23 92 8 4 15 60 7 6 11 44 6 4 5 20 5 1 1 4 |
if X is discrete then:
if X is continuous then:
|
- there are some drawbacks of using the range as the description of the variability of a distribution
-
- the statistic is based solely on the two most extream values in the
distribution, thus it doesn't capture all of the members of the
distribution.
So think back to percentiles. 50%tile equals the point at which exactly half the distribution exists on one side and the other half on the other side.
-
- Considering the same logic, what does the 25%tile represent?
- The 75%?
-
- So using the 25th, 50th, & 75%tiles we can break the distribution into 4
quarters, or quartiles
_X f % c% 7 4 12.5 100 6 4 12.5 87.5 5 4 12.5 75 4 8 25 62.5 3 4 12.5 37.5 2 4 12.5 25 1 4 12.5 12.5 |
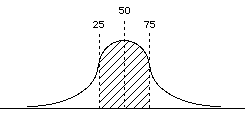 |
So for the above distribution (assume that it is a continuous variable)
-
median = Q2 = 4.0 -> using interpolation (notice exactly halfway between 62.5
& 37.5)
25%tile = Q1 = 2.5 -> the upper real limit for the interval 2
75%tile = Q3 = 5.5 -> the upper real limit for the interval 5
Note that the interquartile range is often transformed into the semi-interquartile range which is 0.5 of the interquartile range.
SIQR = (Q3 - Q1) 2So for our example the semi-interquartile range is (3.0)(0.5) = 1.5
So the interquartile range focusses on the middle half of all of the scores in the distribution. Thus it is more representative of the distribution as a whole compared to the range and extreme scores (i.e., outliers) will not influence the measure (sometimes refered to as being robust). However, this still means that 1/2 of the scores in the distribution are not represented in the measure.
The standard deviation is the most popular and most important measure of variability. It takes into account all of the individuals in the distribution.
In essence, the standard deviation measures how far off all of the individuals in the distribution are from a standard, where that standard is the mean of the distribution.
-
We will begin by discussion the standard deviation parameter, that is the standard
deviation of the population. Then we will discuss the standard deviation
statistic (for the sample). They are closely related descriptive statistics,
but they have some important differences.
So to get a measure of the deviation we need to subtract the population mean from every individual in our distribution.
-
X - m = deviation score
-
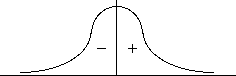
- if the score is a value above the mean the deviation score will be positive
- if the score is a value below the mean the deviation score will be negative
Example: consider the following data set: the population of heights (in inches) for the class
69, 67, 72, 74, 63, 67, 64, 61, 69, 65, 70, 60, 75, 73, 63, 63, 69, 65, 64, 69, 65
mean = m = 67
S (X - m) = (69 - 67) + (67 - 67) + .... + (65 - 67) = ?
= 2+ 0 + 5 + 7 + -4 + 0 + -3 + -6 + 2 + -2 + 3 + -7 + 8 + 6 + -4 + -4 + 2 + -2 + -3 + 2 + -2
= 0
Notice that if you add up all of the deviations they should/must equal 0. Think about it at a conceptual level. What you are doing is taking one side of the distribution and making it positive, and the other side negative and adding them together. They should cancel each other out.
So what we have to do is get rid of the negative signs. We do this by squaring the deviations and then taking the square root of the sum of the squared deviations.
Sum of Squares = SS = S (X - m)2 = (69 - 67) 2 + (67 - 67) 2 + .... + (65 - 67) 2 =
SS = 4+ 0 + 25 + 49 + 16 + 0 + 9 + 36 + 4 + 4 + 9 +49 + 64 + 36 + 16 + 16 + 4 + 4 + 9
+ 4 + 4
SS = 362
The equation that we just used (SS = S (X - m)2) is refered to as the definitional formula for the Sum of Squares. However, there is another way to compute the SS, refered to as the computational formula. The two equations are mathematically equivalent, however sometimes one is easier to use than the other. The advantage of the computational formula is that it works with the X values directly.
The computational formula for SS is:
SS = SX2 - (SX)2 N
So for our example:
SS = [(69)2 + (67)2 + ..... + (69)2 + (65)2] - (69 + 67 + ... + 69 + 65)2 21 = 94631 - (1407)2= 94631 - 94269 = 362 21
Now we have the sum of squares (SS), but to get the Population Variance which is simply the average of the squared deviations (we want the population variance not just the SS, because the SS depends on the number of individuals in the population, so we want the mean). So to get the mean, we need to divide by the number of individuals in the population.
-
Population variance = s2 = SS/N
-
standard deviation = sqroot(variance) = sqroot(SS/N)
s = sqroot(s)
-
s2 = 362 / 21 = 17.24
s = sqroot (17.2) = 4.15
To review:
- step 1: compute the SS
-
- either by using definitional formula or the computational formula
-
- take the average of the squared deviations
- divide the SS by the N
-
- take the square root of the variance
-
- the computations are pretty much the same here
- - different notation:
- s = sample standard deviation
use
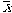 instead of m in the computaion of SS
instead of m in the computaion of SS
- need to adjust the computation to tak into account that a sample will typically be less variable than the corresponding population.
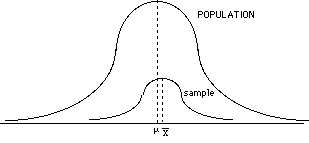
- if you have a good, representative sample, then your sample and population means should be very similar, and the overall shape of the two distributions should be similar. However, notice that the variability of the sample is smaller than the variability of the population.
- to account for this the sample variance is divided by n - 1 rather than just n
sample variance = s2 = __SS _ n - 1
- and the same is true for sample standard deviation
-
sample standard deviation = s = sqroot(SS/(n - 1))
So what we're doing when we subtract 1 from n is using degrees of freedom to adjust our sample deviations to make an unbiased estimation of the population values.