Outline
|
 |
Lab 15
|
|
In our last lab we outlined steps involved in the inferential procedure of Hypothesis testing.
Step 3:Compute a test statistic
Included in our set of statistical tests are three different types of t-tests (we'll discuss these in the next few weeks). We strongly recommend that you download the t-test worksheet booklet and complete the summaries over the next few weeks (as we go through the different t-test labs). Let's quickly recall the decision tree that we saw earlier in the semester. The diagram was designed to help you decide which design describes a research study. You will notice that the diagram you are viewing today has statistical tests added on the right side for each design. This diagram was developed to help you determine which test to use in different situations based on your answer to specific questions about the study you are looking at. The first question asks about the type of research question you are trying to answer. For the tests listed in the chart (and that we are discussing in this class), you are either looking at differences or relationships.
If you are looking for a relationship, you will either use the Pearson r correlation test or the Chi-square test ( we'll discuss these tests in later labs). You can also examine the linear regression line to determine the form of the realtionship. These tests are listed at the bottom of the diagram. The difference between the tests is what type of data you have. For interval-ratio data (numerical scores), use the Pearson r or Linear Regression. For nominal and ordinal data (data are frequency counts), use the Chi-square test. The other tests in the chart look for differences between groups or conditions. The choice depends on several factors: By answering these questions, the chart will lead you to the correct test. Now, let's use the chart to figure out which test to use for different sets of data. Use the chart to figure out which test to use for each study described below. Based on the information given, indicate:
(b) What are the null and alternative hypotheses? (c) What is the appropriate statistical test to compute
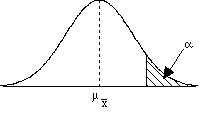
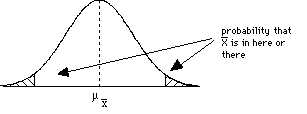
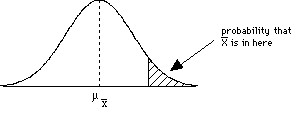
(2) An experiment studied the effect of diet on blood pressure. Researchers randomly divided 54 healthy adults into two groups. One group received a calcium supplement. The other received a placebo. Blood pressure was measured at the end of one month of supplements or placebos. (3) Suppose that during interpersonal social interactions (e.g., during business meetings or talking to causal acquaintances) people in the US maintain an average distance of μ=7 feet from other people. The distribution of distance scores is normal with a σ=1.5 feet. A researcher examines how the US compares in social interaction distance to social interaction distance for people in Italy. A random sample of 40 Italians is observed during interpersonal interactions. For this sample, the mean interaction distance is 4.5 feet. Do the Italians have closer social interactions than Americans do? (4) The animal learning course in a university's psychology department requires that each student train a rat to perform certain behaviors. The student's grade is partially determined by the rat's performance. The instructor for the course has noticed that some students are very comfortable working with the rats and seem to be very successful training their rats. The instructor suspects that that these students may have previous experience with pets that gives them an advantage in the class. To test this hypothesis, the instructor gives the entire class a questionnaire at the beginning of the course. One question determines whether or not each student currently has a pet of any type at home. Based on the responses to this question, the instructor divides the class into two groups and compares the rats' learning scores for the two groups. (5) A scientist investigated the authenticity of ESP abilities by asking subjects who claimed to have ESP abilities to predict the symbol that would appear on the back side of a succession of cards. Each card had a square, a circle, a star, or a triangle. Subjects were informed of this fact and were asked to predict what was on the back of each card as it was held up to them. Because the subjects could not see the backs of the cards, if they had no ESP abilities and simply guessed, they would get an average of .25 answers correct (so μ = .25). The scientist measured how many answers the subjects got correct out of 100 cards. (6) A researcher is interested in how values taught to students by their parents influences their academic achievement. The parents of one group of students is asked to follow a program where they spend one hour per day discussing homework assignments with their child. In the other group, parents are given no program to follow. In order to control for genetic influences on academic achievement, the subjects in the study are identical twins raised apart (i.e., by different parents). One of the twins is randomly assigned to one group and the other twin is placed in the other group. Academic achievement is measured by GPA at the end of the first year of high school. Step 4:Compare the test statistic to a distribution to make an inference about the parameter and draw a conclusion about the sampleAfter computing your test statistic, then you need to make a decision about your hypotheses. This will involve comparing your computed test statistic against a critical test statistic value that is based on your α (alpha-level), and whether you have a 1- or 2-tailed test (and for later tests, something called your degrees of freedom). Let's begin by look at pictures of distributions to try and connect this with what we've been talking about so far. Consider the following sample mean
distributions. The shaded regions
correspond to critical regions that are
defined by a critical test statistic
determined by the alpha level (selected back in
step 1) and whether the hypothesis is 1-tailed
or 2-tailed.
So how do we interpret these graphs?
Putting it all togetherNow let's examine our first statistical test.
One-sample z testAssumptions of the test (and most hypothesis testing)
2) Independent observations -also related to the representativeness issue, each observation should be independent of all of the other observations. That is, the probability of a particular observation happening should remain constant. 3) σ is known and is constant - the standard deviation of the original population must stay constant. Why? More generally, the treatment is assumed to be adding (or subtracting) a constant from every individual in the population. So the mean of that population may change as a result of the treatment, however, recall that adding (or subtracting) a constant from every individual does not change the standard deviation. 4) the sampling distribution is relatively normal - either because the distribution of the raw observations is relatively normal, or because of the Central Limit Theorem (or both). Violations of any of these assumptions will severly compromise any conclusions that you make about the population based on your sample (basically, you need to use other kinds of inferential statistics that can deal with violations of various assumptions)
So far we've been discussing the logic of our Hypothesis Testing procedure. In this lab, we're going to cover one type of test statistic and put all the steps of hypothesis testing together. We're going to conduct hypothesis testing using the one-sample z-test. We've already covered the logic of how this works, but now we'll make it more formal as an inferential test statistic. We can use the decision tree that we saw earlier in the semester (and opened earlier in the lab).
Find the string of decisions that lead to a 1-sample z-test.
Let's look at a complete example using our hypothesis testing steps:
In this study we are comparing a sample to a known population μ and σ. We also know that the distribution of sample means will be normal because our sample size is greater than 30. That means we can use our z-score procedure to conduct this test. Step 1: State hypotheses and decision criterion. For Ha: μseniors
> 4 For H0: μseniors <
4 Since our Ha is a directional hypothesis (we're only predicting an increase in study hours), we'll have a one-tailed test because we'll only need to consider the critical region above the null population mean. We also need to set our alpha level for our decision criterion. We'll use α = .05. This is the highest probability of the null being true that we'll accept as evidence against it.
Step 2: Collect sample data In this step, we actually collect our
data. Suppose we asked the 50 seniors we
selected for our sample how many hours a
week they study and the average reported
mean for the sample was
Step 3: Calculate test statistic The first thing we need to do here is to
calculate the standard error Then we're ready to calculate z: z This is our test statistic. We'll need to know the probability of getting a sample mean this large or larger so we need to find z = 2.86 in the unit normal table. We find that the probability of a sample mean this large or larger is .0021. Now it's time to do our last step to make our decision. Step 4: Make a decision about H0 We need to determine where our test statistic (z = 2.86) falls in the distribution by comparing it's p value with alpha. Is it in the critical region? In this case it is because it is lower than .05 so it would fall in the shaded region. This means there is less than a .0021 chance that we'd get a sample mean of 4.4 if seniors are the same as the general population. Since that's less than .05 (our decision criterion), that's low enough that we can decide that seniors come from a different population with a different mean than the general population of college students. This also means we have enough evidence to reject the H0 hypothesis and accept Ha that seniors study more than the general population of college students. So our decision is: Reject the null hypothesis and accept the alternative hypothesis. Of course remember that there's still a chance (less than 5%) that we made a Type I error, but we're reasonably sure we made the right decision.
(7) Suppose we think
that listening to classical music will
affect the amount of time it takes a person
to fall asleep so we conduct a study to test
this idea.
(b) Assume that the amount of time it takes people in the population to fall asleep is normally distributed. In the study we have a sample of people listen to classical music and then we measure how long it takes them to fall asleep. Suppose the sample of 36 people fall asleep in 12 minutes. What is the probability of obtaining a sample mean of 12 minutes or smaller? Assuming α = .05, is your calculated p value in the critical region (Hint: remember to consider two critical regions)? (c) Using your answer to part (b), what decision should be made about the null hypothesis you stated in part (a)? (d) Assume now that in reality classical music does not affect how long it takes people to fall asleep. In this case, what kind of decision (correct, Type I error or Type II error) have you made in part (c)? Ok, now try a couple more. For problems (8) - (9), write out each step of hypothesis testing. (8) A psychologist
examined the effect of chronic alcohol abuse
on memory. In this study, a standardized
memory test was used. Scores on this test
for the general population form a normal
distribution with μ = 50 and σ = 6. A sample
of n = 22 alcohol abusers had a mean score
of
(9) On a vocational interest inventory that measures interest in several categories, a very large standardization group of adults (i.e., a population) has an average score of μ = 22 and σ = 4. Scores are normally distributed. A researcher would like to determine if scientists differ from the general population in terms of writing interests. A random sample of scientists is selected from the directory of a national science society. The scientists are given the inventory, and their test scores on the literary scale are as follows: 21, 20, 23, 28, 30, 24, 23, 19. Do scientists differ from the general population in their writing interests? Test at the .05 level of significance for two tails. Using the z-test spreadsheetAlthough you can calculate all of these things on your own, Dr. Joel Schneider has made this process easier with another spreadsheet that automates the z-test. Download the z-test spreadsheet. You have to enter the sample mean, population mean, population standard deviation, sample size, and α. You also have to specify which kind of test to perform (2-tailed or which direction the 1-tailed test goes). The standard error, observed z, critical z, and p-value are calculated. In addition, the decision to reject or retain the null hypothesis is printed. You can also look at the graph to see if the observed z falls in the critical region(s). Always check the graph to see if makes sense because it is easy to enter the wrong numbers in the dark gray cells or forget to specify the right kind of test. 
Here is an example that uses this spreadsheet
program to find the solution. Suppose that in the entire telemarketing
sector, employees’ dissatisfaction with their
jobs is μ = 40 and σ = 4
on a questionnaire. Low scores mean happier
workers. High scores mean more dissatisfied
workers. DirectXYZ is a firm that believes that
its policies are significantly better at keeping
its telemarketers happy on the job. At
DirectXYZ, a sample of N = 25
employees randomly selected scored a sample mean
of If the correct numbers and options are entered into the spreadsheet, you can see a tiny red line in the green region at the left. This means that the observed z is in the critical region (i.e., it is more extreme than the critical z.) Thus, the null hypothesis should be rejected. Here is how I would complete the type of questions in the lab:
You will probably have an easier time using the
z-test
spreadsheet described above, however I
strongly suggest that you do the calculations
yourself to make sure that you understand
everything the underlying concepts and then
check your answers using the spreadsheet. |
|||||||||||||
| |
|||||||||||||