A First Course for Students of Psychology and Education, 4th Edition. New York: West Publishing.
Consider the following senario:
-
A researcher is interested in how reading to children affects those kids
own reading ability. The researcher thinks that the age of the child
being read to and how long each reading session is might be important
variables. So the researcher designs the following experiment. Three
groups of children are selected: 3 yr olds, 8 yr olds, & 14 yr olds. Each
group is read a Dr. Seuss story. Within each group, individuals are
randomly assigned to one of three reading conditions. Reading sessions
for group 1 only last 5 mins; 15 mins for group 2; and 30 mins for group
3. After two weeks the kids' reading ability is measured (with age
appropriate standardized books).
| Reading session duration | ||||
| 5 mins | 15 mins | 30 mins | Age |
3 yrs | 8 yrs | 14 yrs |
T-tests and z-scores are great but they are limited, they can't be used for more than 2 groups. Instead what we need to do is use a new inferential statistical procedure: Analysis of Variance (ANOVA).
-
In analysis of variance, a factor is an independent variable. A study
that invloves only one independent variable is called a single-factor
design. A study with more than one independent variable is called a
factorial design.
The individual treatment conditions that make up a factor are called levels of the factor.
So the study described above is a factorial design, with two between groups factors, and each factor has 3 levels (sometimes described as a 3 by 3 between groups design).
We'll start with by talking about the overall logic of ANOVA, and discuss some new notation. Then we'll work through the process and some examples. We'll end the chapter with a discussion of post-hoc tests (don't worry about what these are, yet).
We'll be using the same hypothesis testing logic that we used in chapters 8-11, but the details will change (as they did from chapter to chapter).
-
step 1: state your H0 (and H1 ??) & figure
out your critera: a = ?
step 2: the ANOVA test is always one-tailed
step 3: figure out the df for your test (there will be two dfs)
step 4: find the critical f-statistic from the table (new table A-29)
step 5: compute your f-statistic for your samples
step 6: compare your f-statistic with the critical f-statistic
step 7: make your conclusions about the H0
Okay, let's consider a new example that is a single-factor, independent-measures research design.
-
Suppose that for your senior research project you decide to test the
effectiveness of three different studying methods on learning. Method A,
is to have students only read the textbook, but not go to class. Students
assigned to Method B, go to class and take notes, but don't read the
textbook. Students the the Method C group don't read the textbook or go
to class, they just get to look at another student's class notes
-
H0: m1 = m2 = m3
H1: one of the groups is different from one or more of the other groups so there are really lots of possible alternative hypotheses
-
m1 not equal to m2 = m3
m1 = m3 not equal to m2
m1 = m2 not equal to m3
m1 not equal to m2 not equal to m3
Often, people will just give the null hypothesis, because there are just too many alternatives (imagine how many we could have for our orignal 3X3 design)
insert figures here step 3: figure out the df for your test. We'll save this for a little later when we start using a concrete example. One thing to note is that we're going to have several dfs to consider (or worry about, if that's the way you feel).
step 4: find the critical f-statistic from the table (new table starting on pg 695)
| df in the numerator | |||||
| df in denominator | 1 | 2 | 3 | 4 | 5 |
| 1 |
161 4052 |
200 4999 |
216 5403 |
225 5625 |
230 5764 |
| 2 |
18.51 98.49 |
19.00 99.00 |
19.16 99.17 |
19.25 99.25 |
19.30 99.30 |
| 3 |
10.13 34.12 |
9.55 30.92 |
9.28 29.46 |
9.12 28.71 |
9.01 28.24 |
|
: : |
: : |
: : |
: : |
: : |
: : |
-
As was the case with the t-table, the f-table describes a family of
f-distributions.
Recall that we'll have two dfs, we use one to find the correct row and the other to find the correct column. You'll also note that there are two numbers per cell. The lighter numbers correspond to a = 0.05, the bold numbers correspond to a = 0.01.
-
Okay, here is where things will start to get complex. For now, we'll
stick
with talking about things at the conceptual level (no computations yet).
In many ways the ANOVA is very similar to a two independent smaples t-test (in fact we'll later we'll talk about how they are nearly identical under certain circumstances).
tobs = obtained difference between sample means difference expected by chance= insert formula for independent samples t-test here
- remember the pop mean part = 0, so what we're left with is a
difference between the sample means
For ANOVA the test statistic (called the F-ratio) is similar
F = variance (differences) between sample means variance (differences) expected by chance (error)
Why do we have to use variance?
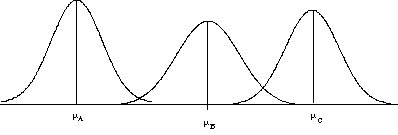
-
Because we have more than two groups.
How would we compute a single score that would describe the difference between these distributions? Difference just doesn't cut it, but variance does (recall it is a measure of how these much these three distributions differ from oneanother).
Notice that this is how ANOVA gets its name. Analysis of Variance.
-
Treatment/group effects - the treatment caused the differences
Individual difference effects - differences due to differences in individuals
Random (experimental) error - just what it sounds like, random error
-
Individual difference effects
Random (experimental) error
BUT NOT treatment/group effects - this is the key
So the F-ratio can be expressed as:
F-ratio = variance (differences) between sample means variance (differences) expected by chance (error)F-ratio = variance between treatments variance within treatments
F-ratio = treatment effect + individual differences + random error individual differences + random error
-
Note: sometimes you'll hear the denominator referred to as the error
term- it provides a measure of the variance due to chance
if H0 is true, then what should the value of the treatment effect be?
H0: m1 = m2 = m3
so there are no difference, so variance should be = 0
If variance = 0, then what is the value of the F-ratio?
F-ratio = 0 + individual differences + random error = 1 = 1.0 individual differences + random error 1
of H0 is false, then the F-ratio will be greater than 1.
 i)2
i)2