Psychology 345 SPSS Page
Computer Applications in Psychology
Illinois State University
J. Cooper Cutting
Spring 1999, Sections 01 & 02

Introduction to SPSS
Data Analysis
Testing hypotheses involves conducting a study
Conducting a study involves translating variables into numbers
ex. depression = 0 to 63, gender = 0 or 1, treatment = 0 or 1
Working with numbers involves data analysis
What is SPSS?
SPSS is software that describes, displays, and analyzes data
SPSS can be accessed:
...in this classroom
...in the Schroeder 344 computer lab
...in the Milner Library computer lab
...at home if you buy SPSS at the bookstore
Elements of the SPSS Screen
SPSS File Management
Working with existing files
"Open" a file
"Save" file and "Save As"
Creating new files
Define variables (double click) to give name, type (numeric or string), and labels (variable labels and value labels)
Enter data
click here to see the file menu.
SPSS Activity
Create a spss data file; save as yourname.sav
Create a variable called "age"
Label it "Age of participant"
Create a variable called "name"
Make it a string variable
Create a variable called "gender"
Make value labels 0 and 1
Sort the datafile by gender.
Data Management Tips
Label all variables and values
Make sure no value is out of range
Let missing values be a "."
Backup your file often
Survey Example
Research question - Is social support related to self-esteem?
Hypothesis - Scores on the Social Provisions Scale will show a positive correlation with scores on the
Rosenberg Self-Esteem Scale
Choose Transform, Recode from menu bar
Into same variables
Into different variables (choose new name)
Recoding Into Same Variables
Assigns new values to a variable based on the old values of a variable
Reverse scoring is a common application
Many scales have items worded in two directions
All items must be scored so they are in the same direction
Indicate old and new values, then click "Add"
Repeat process until all values are in box
Click "Continue"
screen 1 screen 2
Recoding Into Different Variables
Assigns new values to a new variable based on the old values of a variable
Select the old variable to be recoded
Type in the name of the new variable & click "change"
Indicate old and new values, then click "Add"
Repeat process until all values are in box
Click "Continue"
screen 1 screen 2
Recode Activity
Open grades.sav from your book's data disk
Look at the value labels for year
Recode so 1=4, 2=3, 3=2, and 4=1
Creates a new variable and values for that variable based on an expression
Computing scale totals is a common application
Allows multiple scale items to be summed
Individual items are not typically used in data analysis in psychology
Choose Transform, Compute
Review of Compute Process
Enter the name of your new variable under "Target Variable"
Enter numeric expression by typing or using calculator pad
For quicker calculations, use "sum" function
Separate variable names by commas
If consecutive, use "to" (e.g., "var1 to var10")
Use "mean" function to avoid problems with missing values
Use it like "sum" function
Multiply mean by number of scale items to retain original range of scores
Compute Activity
Add all of the quizzes using the calculator pad, and call new variable quiztot
Conditional Transformations
Purpose is to create new categorizations based on values of existing variables
Recode Into Different Variables is one way to do this
Compute a new variable is another way
Transformation Cautions
Remember to save data set so changes are saved on your file
Never recode variables into same variable more than once or you'll get confused
Be aware of how you're handling missing data
Pie chart -- illustrates percentages or frequencies as a slice of a whole pie
Bar chart -- illustrates percentages or frequencies with category labels on the X-axis of a graph
Line plot -- a line chart for continuous data, such as interval or ratio data; has numeric values on the X-axis
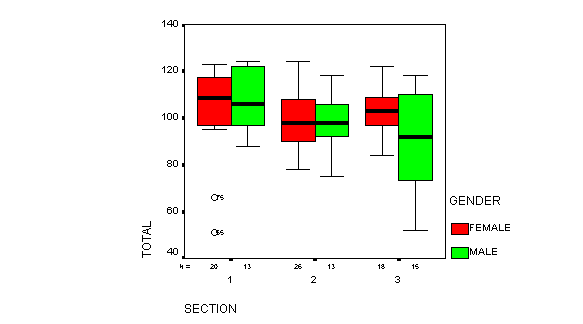
Box Plots -- a way of representing distributions, plotting the min, max, 1st and 3rd quartiles, and the median
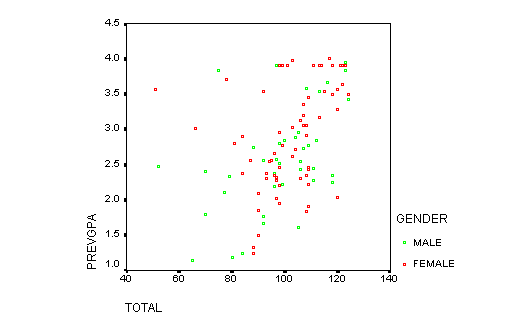
Scatterplots -- used for plotting 2 (or more) variables against oneanother to examine if they are related or not
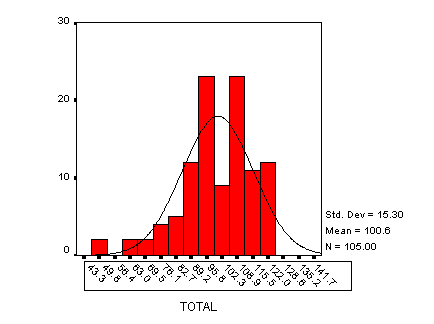
Histogram -- a bar chart for continuous data, such as interval or ratio data; has numeric values on the X-axis
nominal
ordinal
interval
ratio
Calculates how many times a certain score was obtained on a variable
Percentages can be tabulated (e.g., percentage of women or men in a study)
Typically most useful for nominal data
Not a test of hypotheses, but frequencies can provide interesting information
Frequencies and Percentages
Choose Statistics, Summarize, Frequencies
Select variable(s) to summarize
Output includes:
Frequency
Percent
Valid percent
Cumulative percent
Measures of central tendency
Measures of distribution shape
Measures of distribution variability
Percentiles
Frequency Options
Choose format to sort order of output
ascending values (default)
descending values
ascending counts
descending counts
Exercise: Compute frequencies for richwork, satjob, and life from gss.sav file
Creating Categories
Nominal data can be created from ordinal, interval, or ratio data
Ordinal data can be created from interval or ratio data
Median is used to create two equal sub-samples based on score of a variable
Quartiles are used to create four equal sub-samples
Crosstabs Example
Do people with different work statuses (e.g., full-time, retired, etc.) differ in (a) how exciting life is
and (b) happiness?
This amounts to tabulating frequencies for life excitement and happiness, but it must be broken down
by work status
Crosstabs gives frequencies for one variable separately for each level of another variable
Choose Statistics, Summarize, Crosstabs
Select categorical variables; put one in Row and the other in Column
Output:
Case Processing Summary shows missing values for each table
Crosstab shows frequencies of one variable for each level of the other
Choose Cells, Row Percentages to show percentages across each row
Choose Cells, Column Percentages to show percentages across each column
Choose Cells, Total Percentages to find percentage of respondent that were in each cell
Expected Counts
Expected counts are based on marginal percentages
Multiply the marginal percentages together to get the expected percentage for that cell, then multiply
by N to get expected counts
Or, have SPSS compute them -- Choose Cells, Expected Counts
Residuals
Difference between expected and observed counts
Choose Cells, Unstandardized Residuals
Standardized Residuals are distributed as z-scores (they were divided by the standard deviation of the
residuals)
Controlling for a Third Variable
Controlling for a variable means it is held constant
This allows us to look at crosstabs separately for each value of a third variable
Example: wrkstat by life separately for men and women
In SPSS add sex as a layer in Crosstabs
Bar Charts
Simple
Can only show frequencies of one variable
Choose Graphs, Bar, Simple
Cluster and Stacked
Can show frequencies of one variable broken down by another
Percentage information can also be shown
Crosstabs
Compute percentages of happy for different values of wkstat
Compute percentages of wkstat for different values of life; include expected values and residuals
Compute percentages of wkstat for different values of life, layered by gender
Compute bar charts for wkstat by life
Chi-Square (c2)
Chi-Square Lecture
Chi-Square Example
Research questions - Are there gender differences in happiness? How about in how important it is to
have a fulfilling job?
What would you hypothesize?
The hypothesis test for whether the pattern of percentages in one variable differs as a function of
another is called the chi-square test
Hypothesis Testing
We test the null hypothesis that nothing interesting is happening (versus alternative hypothesis that
findings are interesting)
The null hypothesis can only be rejected if there is a .05 probability that our findings are due to chance
Hypothesis tests determine the extent to which our findings may be due to chance
The Pearson Chi-Square Test
The chi-square test essentially tells us whether the results of a crosstab are statistically significant
A chi-square will be significant if the residuals for one level of a variable differ as a function of
another variable
The chi-square value does not tell us the nature of the differences
The Chi-Square Formula
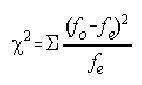
What are all those symbols?
c2 = chi-square
S = Sigma (sum of...)
fo = frequency observed
fe = frequency expected
Degrees of freedom are necessary to compute the significance of the chi-square: df = (#rows -
1)(#columns - 1)
Assumptions of the Chi-Square
Categories are independent (no overlap)
Must have an expected count of at least 5 in each cell
Remember that large samples mean large chi-squares, thus making it easier to find a significant
chi-square (this is called power)
Run Crosstabs procedure and enter variables in columns and rows
Choose Statistics, Chi-Square
Output shows Pearson chi-square and "Asymp. Sig." (significance level)
If "Asymp. Sig." is less than .05 then the residuals differ as a function of the independent variable
Chi-Square Exercise
Examine gender differences for degree (highest degree earned), degree2 (college degree-yes or no),
and satjob2 (satisfied with job-yes or no)
What would you hypothesize?
Examine chi-square values, p levels, and crosstab to see if hypotheses are correct
Are degrees of freedom are accurate?
Variability provides an estimate of how much scores within a group of scores varied
range -- difference between high and low scores
variance -- average squared deviation from the mean (Sum[X - M]2 / N - 1)
standard deviation -- average deviation from the mean (square root of variance)
Frequencies
Choose Statistics, Frequencies
Select variables
Choose "Statistics"
Descriptives
Choose Statistics, Descriptives
Select variables
Choose "Options"
Normal Distributions
No skew (lopsidedness of the distribution)
mean > median = positive skew
mean < median = negative skew
No kurtosis (peakedness or flatness)
negative value (very flat) is undesirable
positive value (very pointed) is also undesirable
Skew and Kurtosis in SPSS
Choose Statistics, Descriptives
Choose "Options"
Select skew and kurtosis
Interpretation of Skew and Kurtosis Output
Divide Skew by SE Skew and divide Kurtosis by SE Kurtosis
Values of 2 or more suggest skew or kurtosis
Viewing Normality of Distribution
Choose Charts, Histogram
Enter variable
Check "Display normal curve"
A z-score is a standard score obtained by subtracting the mean from a score and dividing by the
standard deviation
In SPSS, Compute a new variable
Or, choose Descriptives and "save standardized values as variables"
Comparing means allows us to look at differences between groups of participants
Choose Statistics, Compare Means, Means
Continuous variables go in Dependent List
Grouping variable goes in Independent List
Under "Options," choose statistics
Enter second categorical variable as layer
Plotting Group Means
Choose Graphs, Bar, Simple, Define
Choose "Other summary function" and enter dependent variable
Independent variable is "Category Axis"
Under "Options," uncheck "Display groups defined by missing values"
A Clustered Chart can be used for a second grouping variable
Null Hypotheses About Sample Means
One-Sample T Test
Used to compare a sample mean with a known mean in the population
Example-Do college graduates work an average of 40 hours per week?
Based on the null hypothesis, we assume that the population mean is 40 (this may or may not be true)
Statistical Theory of the One-Sample T Test
To address our null hypothesis we compute a standard score
Remember that a z-score is the score minus the sample mean divided by the standard deviation
Since we're working with a population and not a sample, we use different numbers and compute a t statistic (not to be
confused with a T Score)
The T Statistic
The t statistic is the sample mean minus the population mean divided by the standard error of the mean
standard error of the mean refers to the variability of sample means drawn from the same population
computed by dividing the standard deviation by the square root of N
The T Test
The t-test indicates the probability that the difference between the sample mean and the population mean is due to chance
Probabilities of .05 or less are significant
Differs from z-score probabilities in that t statistics are sensitive to small sample sizes
Choose Statistics, Compare Means, One-Sample T Test
Choose variable to test
Select known population mean under "Test Value"
Select "OK"
Confidence intervals
One-Sample T Test Output
Descriptives (N, mean, standard deviation, standard error of the mean)
T value (mean difference divided by standard error of the mean)
Degrees of freedom (which is N - 1)
Significance level (two-tailed does not hypothesize a direction; one-tailed does)
Mean difference
95% confidence interval -- the interval in which we can be 95% confident that the true difference between means is (other
intervals can be computed using the "Options" button)
One-Sample T Test Exercise
Open "gssft.sav"
Do respondents with less than a high school degree (degree = 0) have income (rincmdol) equal to the poverty threshold
($8,178)?
Examine respondents with a high school degree or less (degree = 0 or 1) and see if they make $20,000.
Paired-Samples T Test
Used to compare two means from a sample obtained under different situations
Also used to compare two means from matched samples
Example-Do runners' endorphin levels change after running a marathon?
Statistical Theory of the Paired Samples T Test
If the two related means are equal in the population (under the null hypothesis), the difference between two related means
should be 0
Creating a difference score allows one to use the one-sample t test
A paired-samples t test can be used without computing the difference score
Choose Statistics, Compare Means, Paired Samples T Test
Select the two variables to test
Select "OK"
Paired-Samples T Test Output
Statistics are given as in the one-sample t test
Correlation between two means (we'll talk more about correlation soon�)
T test results are interpreted as before
Independent-Samples T Test
Used to compare means from two independent samples
independent-there is no relationship between people in the different groups
Examples-Do women and men have similar levels of self-esteem? Do freshmen and seniors have similar levels of social
support?
Rationale of Indep.-Samples T
The one-sample t-test compares a sample mean with a population mean
The paired-samples t-test compares the difference between two related sample means and 0
The independent-samples t-test compares the difference between the two independent sample means and 0
The T Statistic (again?)
Subtract the difference between the two population means (0) from the difference between the two sample means
Divide this by the standard error of the mean difference and interpret as usual
Standard Error (again?!?)
The standard error of the mean difference accounts for the standard deviations of both groups
This is calculated in one of two ways depending on whether or not the variances of the groups are equal
SPSS shows two different T statistics, only one of which is correct (yikes!)
So which T do we use?
Levene's Test is used to determine which T statistic to use
If the F statistic is significant the variances are unequal -- so use the unequal-variance T statistic
SPSS automatically performs Levene's test when you perform the independent-samples t-test
Choose Statistics, Compare Means, Independent-Samples T Test
Select dependent variable to test
Select independent/grouping variable
Define groups by entering the value of each group
Select "OK"
Group descriptives
Levene's test
equal variances assumed if F statistic is not significant
equal variances not assumed if F is significant
T statistic and significance level (be sure to look at correct T statistic)
Displaying Mean Differences
Use a Simple Bar Chart
Dependent variable under "Other summary function"
Independent variable under "category axis"
Don't display a group defined by missing values
To change y-axis
double-click chart to get to Chart Editor
double-click y-axis to change scale
under "Range" choose a wider range
perhaps change "Major Divisions"
If more than two groups are defined by a variable then select cases so you just have the two groups
Analysis of variance--called ANOVA
Tests the null hypothesis that the means of two or more groups are equal
Alternative hypothesis is that at least one group differs significantly from one or more of the others
Fundamentals of ANOVA
Independent variable is categorical (e.g., year in school, experimental condition)
The independent variable is often called a "factor"
ANOVA is unlike a t-test in that more than two groups are permitted
Dependent variable is continuous
Assumptions of ANOVA
Observations are independent of one another
The continuous dependent variable is distributed close to normal
The variance of the continuous dependent variable is roughly equal in all groups
How ANOVA Works
ANOVA analyzes variance by separating it into two parts
Within-groups variability
Between-groups variability
F statistic indicates whether the between-groups variability is significantly greater than the
within-groups variability
If the F statistic is significant (p < .05), at least one group mean is significantly different from one
or more of the others
A significant F statistic suggests that we reject the null hypothesis
One-WayANOVA in SPSS
Choose Statistics, Compare Means, One-Way ANOVA
Enter the continuous dependent variable in the Dependent List
Enter the categorical independent variable in the Factor box
The ANOVA Table
Sum of squares
between groups: G[(group mean - overall mean)2*n]
within groups: G(group variance * n)
Degrees of Freedom
between groups: # of groups minus 1
within groups: G(n - 1)
Mean square
The estimate of variability
sum of squares divided by degrees of freedom
F statistic
MS between / MS within
Significance level of F
Follow-Up Analyses
Multiple comparison procedures indicate where the significant difference is in an
ANOVA
known as a post hoc test
The Bonferroni procedure is a series of t-tests with an adjusted significance level
Computing Post Hoc Tests
In One-Way ANOVA, choose Post Hoc
Check Bonferroni
Choose "Continue"
Two-Way ANOVA
One-way ANOVA examines whether the means of two or more groups differ
Two-way ANOVA allows us to add a second factor (independent variable)
Purpose of Two-Way ANOVA
Tests the null hypothesis that the means of all groups of Factor 1 are equal
Tests the null hypothesis that the means of all groups of Factor 2 are equal
Tests the null hypothesis that the relationship between each factor and the dependent variable is the same for all levels of the
other factor
Types of Effects in Two-Way ANOVA
Main effect
The effects of each individual factor
Ignores the level of the other factor
Interaction
The cumulative effect of two variables
Present when the relationship between one factor and the dependent variable changes for different levels of the other
factor
Two-Way ANOVA in SPSS
Choose General Linear Model, Simple Factorial
Enter dependent variable in "Dependent" box
Enter the two factors in "Factor(s)" box and define ranges
Choose "OK"
Two-Way Output
The main effects are listed first with their own F statistics
The interaction effect is then listed with its own F statistic
"Residual" is analogous to the "Within-Groups" of One-Way
Plotting Interactions
Clustered bar chart
Enter Dependent variable in "Other Summary Function"
Enter one factor as "Category Axis" and the other as "Define Clusters By"
Multiple line chart
Set up the same way as a clustered bar chart
Final Thoughts
Assumptions for the two-way ANOVA are the same as for the one-way ANOVA
If the interaction is significant it does not make sense to interpret main effects
Does self-esteem increase as one's social support increases?
Do psychiatric symptoms decrease as one's social support increases?
Correlation and regression are appropriate tests of the relationship between two continuous variables
Basics
Correlation describes the relationship between two continuous variables
Correlation and regression test the null hypothesis that the two variables are independent of one another
Regression allows one to predict scores on one variable given a score on another
Let's Start With Scatterplots
A visual description of the relationship between two continuous variables
In SPSS choose Graphs, Scatter, Simple, Define
Select X-axis and Y-axis variables as independent and dependent
Scatterplots do not always clearly show a relationship
The Correlation Coefficient
The correlation coefficient ("r") gives two pieces of information:
strength of relationship, measured by absolute value
direction of relationship, indicated by a positive sign or negative sign
Correlations in SPSS
Choose Statistics, Correlate, Bivariate
Enter the two variables in the "Variables" box
Select "OK"
Is correlation significant?
If so, is it positive or negative?
Correlation and Causality
Correlation does not imply causality
Conditions for causality
Temporal sequence
There is a relationship (correlation) between two variables
Relationship cannot be explained by a third variable
Linear Regression
Used to predict one's score on a variable given a score on a second variable
The mean is the best predictor of a variable (let's call it "Y") in the absence of any other information
With information about a related independent variable, prediction can be improved
The Regression Line
A regression line provides more precise predictions than simply predicting the mean for each observation
Regression line is Y = a + bX
"a" is the intercept (value of Y when X=0)
"b" is the slope (change in Y per unit increase in X)
Using the Regression Line
Use number of close friends to predict number of health center visits per year with this regression line: Y = 5 + (-1)X
Use number of close friends to predict number of late-night phone calls per week with this regression line: Y = 1 +
(0.5)X
Explaining Variance
"Explaining variance" is the extent to which an independent variable accounts for variation in the dependent variable
Percentage of variance explained is found by squaring the correlation (R2)
Regression in SPSS
Choose Statistics, Regression, Linear
Enter dependent variable in the "Dependent" box
Enter independent variable in the "Independent" box
Select "OK"
Interpreting Output
Model Summary -- shows r and R2
ANOVA table -- shows significance of r and R2 as an F statistic
Coefficients -- shows the regression line
Under B column is intercept and slope
Beta column shows standardized slope (the correlation)
Significance of slope is indicated by t
Assumptions and Cautions
We assume the relationship between X and Y is linear
We assume the variance of Y is equal at all values of X (homoscedasticity)
Do not assume causality
Return to the psych 345 syllabus page.
Return to Illinois State University Home Page
Return to Illinois State University Psychology Home Page
If you have any questions, please feel free to contact me at
psych345@hotmail.com.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}